| Page Properties | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| Table of Contents |
|---|
Introduction
The purpose of this document is to record the results of the requirements gathering process carried out for the Open, Reusable Knowledge graph Annotator (ORKA) and NanoPub Store products in the context of the ODEX4all project, as well as describe the software specification for the two systems. This project uses an adapted version of the Agile and Scrum methodologies. This adaptation is required by some of the characteristics of the project such as the distributed nature of the development team, the collaboration with other teams from different products and projects, and the possibilities of dynamic variations of the team members. To adapt the classical Agile and Scrum methodologies to the characteristics and needs of ODEX4all, the two main changes has been defined as: (a) more time is dedicated to the analysis and design phase of the development to allow for more detailed specifications of the systems to be developed, and (b) instead of daily stand-up Scrum meetings and long Sprint and evaluation meetings, the team will rely more heavily on online Scrum supporting tools such as Jira, Jira Agile, Jira Portfolio and Atlassian Confluence, with a significant part of the team interaction taking place on electronic means such as Skype calls, instant messaging, etc.
...
From the usage scenarios described in Section 2.1, the use cases depicted in Figure 1 have been derived.
 |
Figure 1 - Use cases |
The actors of the use case are divided in two types of users, namely, the NanoPub Author and the NanoPub User. While the former interacts with the system for the purpose of annotating an assertion, publishing the assertion or managing the assertions he published, the later consumes the published assertions by means of searching, retrieving and citing the assertions.
...
From the use cases described in the last session, we have decided to split the expected functionality of the system in two separate applications, namely, ORKA and NanoPub Store. ORKA is responsible for providing support to users who want to annotate a triple originated from a graph analysis tool by changing the triple's predicate. The edited triple is then transformed into a nanopublication adding the provenance of the author and keeping the relationship with the original triple. The NanoPub Store is responsible for storing the nanopublications created in the Triple Annotator as well as allowing users to search for stored nanopublications and cite them.
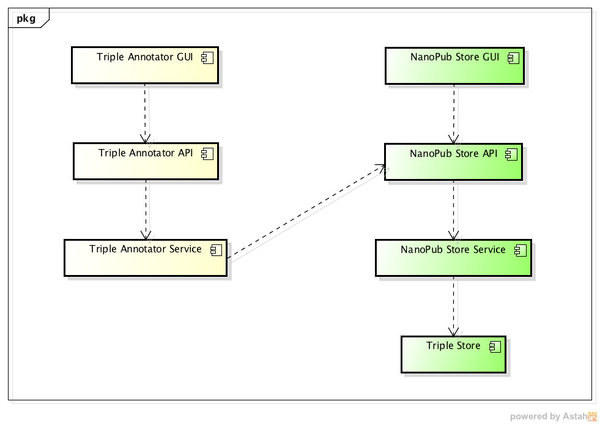 |
Figure 2 - General architecture of ORKA and NanoPub Store applications |
Figure 2 depicts the general architecture of ORKA (yellow) and NanoPub (green) applications. The applications have been divided in the following three main integrated but independent layers:
...
The argument for the annotation() call is specified below as "Data Model 1".
Self-referring Annotator calls may be implemented as communication between annotator front-end and back-end.
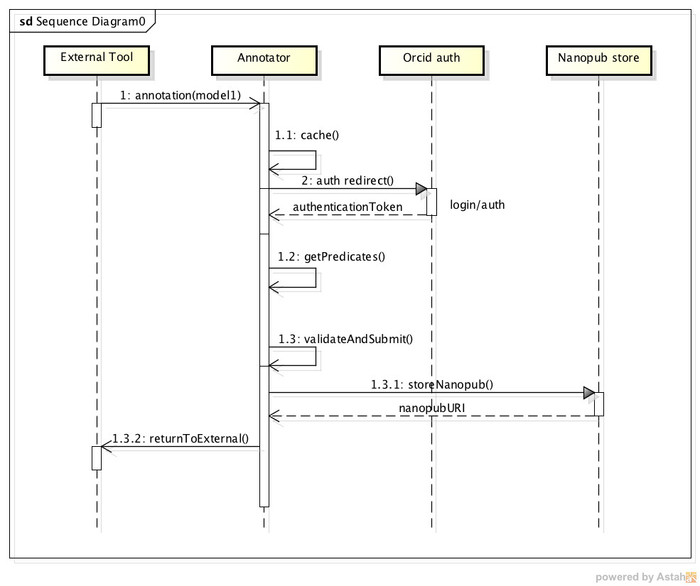
APIs
Annotation (implemented)
type: GET
path: http:/api/annotation/semlab1.liacs.nl:8081/annotator/entry
parameter 1: original triple and referrer (see JSON model 1)
desc: entry point for external tools to initiate annotation
returns: -
Get Predicates (not yet implemented)
type: GET
path: /api/predicates
parameter 1: -
desc: list known predicates, a simplistic approach in making a static list of predicates available
returns: an array of predicate URIs and a label (see JSON model 2)
...
JSON data model 1
Current:{
"subject": "aspirin",
"subjectUri": "http://example.com/aspirin",
"predicate": "treats",
"predicateUri": "http://example.com/treats",
"object": "smoking",
"objectUri": "http://example.com/smoking",
"returnUri": "http://semlab1.liacs.nl:8081/annotator-demo/complete.html",
"returnLabel": "Annotation Demo"
}
Previous:{
“subject”: { // original triple subject
“label”: “”,
“uri”: “”
},
“predicate”: { // original triple predicate
“label”: “”,
“uri”: “”
},
“object”: { // original triple object
“label”: “”,
“uri”: “”
},
“referrer”: { // models the source application
“label”: “”, // text of the return button
“returnTo”: “”, // return button url
“version”: “” // metadata for the nanopub provenance
}
}...