ORKA and NanoPub Store Software Specification
Introduction
The purpose of this document is to record the results of the requirements gathering process carried out for the Open, Reusable Knowledge graph Annotator (ORKA) and NanoPub Store products in the context of the ODEX4all project, as well as describe the software specification for the two systems.
Goals
- Allow users/curators to annotate any existing (RDF) graph.
- Should provide some UI to allow users to “edit” a triple and help the user to locate suitable RDF identifiers for S, P, O.
- Final annotation will be stored as an open-access nanopublication which may be ingested by the original source or used in other ways.
- To be implemented as a generic (web) service that can be called from other tools (e.g. BRAIN).
Usage Scenarios
From the initial discussions regarding ORKA and NanoPub Store, the following usage scenarios have been defined to guide the requirements gathering and consequent design and development of the solution.
Triple Annotation
An analyst, using a graph-based analysis tool wishes to edit a certain assertion. The edition of an assertion may have different motivations, such as: the analyst disagrees with the assertion, the analyst wants to define a different predicate for the assertion, the analyst wants to express his agreement with the assertion, etc.
Since the analyst is not the creator/owner of the dataset where this assertion has been originally defined, this edition should be seen as a different piece of knowledge, maintaining, of course, the relation with the original assertion.
Triple citation
A user, utilizing a graph-based analysis tool finds an assertion for which he wants to have a publicly resolvable identifier in order for him to be able to cite the assertion. To be able to properly cite the assertions, they should also contain provenance information about the author(s) of the assertion, publication date, origin, etc.
Assertion discovery
Users would like to search for available assertions for citation of the assertions or integration of the knowledge represented in the assertions with different pieces of knowledge or data. Therefore, the search results should be both in a format that human users can verify that the result matches his expectations and in a format that can be easily integrated with other datasets.
Use Cases
From the usage scenarios described in Section 2.1, the use cases depicted in Figure 1 have been derived.
 |
Figure 1 - Use cases |
The actors of the use case are divided in two types of users, namely, the NanoPub Author and the NanoPub User. While the former interacts with the system for the purpose of annotating an assertion, publishing the assertion or managing the assertions he published, the later consumes the published assertions by means of searching, retrieving and citing the assertions.
To guarantee the proper provenance of the published/edited assertion, the NanoPub Authors are required to provide his unique identification that will be part of the new publication. The system also requires the NanoPub Author to provide his unique identification to allow the management of all the assertion published by that author.
In the figure, 3 main use cases are defined for the NanoPub Author. The author can annotate (edit) a selected triple he found in a graph analysis tool, can publish a given triple in terms of a nanopublication without editing it, and can list all his/hers published nanopublications.
For the NanoPub User, 3 other use cases have been defined. The user can search for nanopublications, once a nanopublication has been found and selected, the user can retrieve it (for instance, to include the nanopublication in a graph) or cite it using its resolvable id.
System Architecture
From the use cases described in the last session, we have decided to split the expected functionality of the system in two separate applications, namely, ORKA and NanoPub Store. ORKA is responsible for providing support to users who want to annotate a triple originated from a graph analysis tool by changing the triple's predicate. The edited triple is then transformed into a nanopublication adding the provenance of the author and keeping the relationship with the original triple. The NanoPub Store is responsible for storing the nanopublications created in the Triple Annotator as well as allowing users to search for stored nanopublications and cite them.
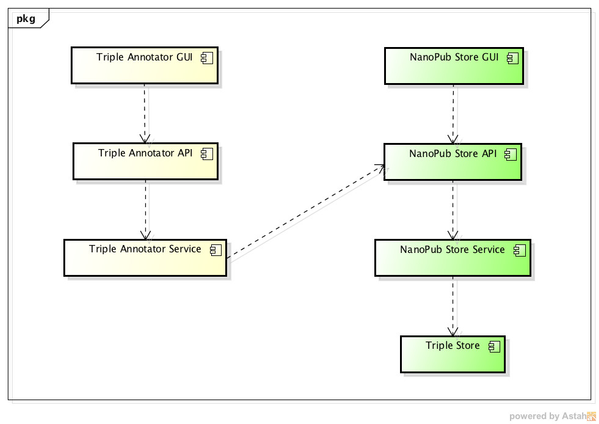 |
Figure 2 - General architecture of ORKA and NanoPub Store applications |
Figure 2 depicts the general architecture of ORKA (yellow) and NanoPub (green) applications. The applications have been divided in the following three main integrated but independent layers:
- Graphical User Interface (GUI) layer - a browser-based user interface supporting the interactions of the applications users. The functionality of the two services are accessible to the users through these interfaces.
- Application Programming Interface (API)layer - the APIs provide access to the applications functionalities to other software systems. The user's analysis graph tool submits the selected triple for annotation using the Triple Annotator's API. Similarly other tools or the Triple Annotator stores nanopublications using the NanoPub Store API. For both applications, their GUIs also interact with their respective APIs.
- Service layer - the service layer contains the business logic of the applications. This layer is only reachable form the API layer, providing isolation to the business logic.
In the case of the NanoPub Store, an another layer is needed to provide the actual storage facility. Since nanopublications are based on RDF, the storage facility is depicted in Figure 2 as the Triple Store component.
This multi-layered approach support the following non-functional requirements:
- Modularity and separation of concerns - by splitting the functionality in different component layers, the development of each layer can focus on the aspects covered by that layer, such as graphical user interface, application programmable interface and business logic.
- Maintainability - as long as the communication interfaces among the layers are intact, modifications on the code of one layer do not affect the other layers, facilitating maintenance of the code.
- Scalability - having the separate layers facilitates scalability since the components of each layers can be deployed in different servers, profiting from infrastructural scalability mechanisms such as load balancing and elasticity.
User interaction
ORKA
Figure 3 depicts a basic sequence of interactions of ORKA for the use case of triple annotation. This interaction starts on the graph tool where the NanoPub Author selects a given triple to be edited. From the graph tool, the author exports the selected triple represented as a nanopublication to ORKA (sequence 1 in the figure). Since ORKA properly stores provenance information of the nanopublications, it requires the author to provide a unique and resolvable identification. This identification is provided by an Authentication Provider such as ORCID, Google and Facebook. Once a nanopublication is received by ORKA, the system invokes the Authentication Provider requesting the authentication of the author. After the author successfully authenticates his credentials on the Authentication Provider, the provider returns to ORKA an authentication token. By using a third party authentication provider, the Triple Annotator does not need to manage user’s credentials and the users do not need to remember another set of username and password.
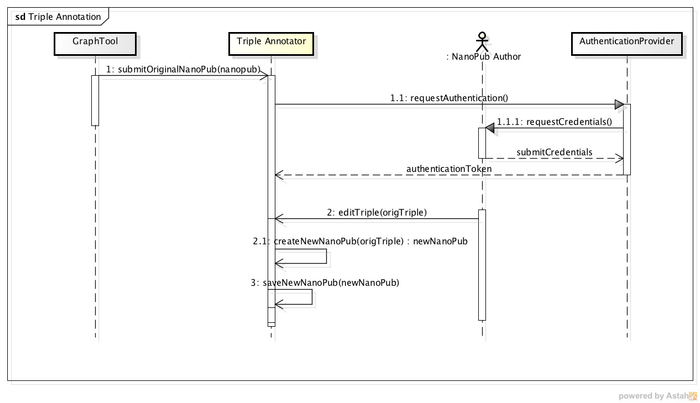 |
Figure 3 - Interaction sequence for triple annotation |
Once the NanoPub Author is properly authenticated, the Triple Annotator interface provides the facilities to allow the author to edit the original triple (sequence 2). When the author starts editing the triple, the Triple Annotator creates a new nanopublication with the same object, subject and predicate (sequence 2.1) as the original triple adding the provenance information of the authenticated NanoPub Author and the reference to the original triple. In this way, the Triple Annotator maintains the provenance chain. The new nanopublication is then stored in the system.
Triple citation
Assertion discovery
Attaching evidence to an annotation
Knowledge graph annotations are more valuable in terms of reusability if the annotator can provide supporting evidence. Here we focus on evidence taken from scientific literature, although other sources of supporting evidence may exist: databases, technical reports, electronic lab notebooks, etc. Yet another category consists of (relatively) weak types of evidence: like-buttons, vote up/down, etc.
Here we propose several scenarios of literature-based evidence based on the PubAnnotation community framework.
Scenario 1: cite a document fragment
- user provides PMID
- ORKA retrieves abstract from PubAnnotation
- user selects a fragment (words or sentences) that support his annotation
- ORKA records the PubAnnotation fragment URI as supporting evidence in the nanopublication
Scenario 2: cite an existing annotation
- user provides PMID
- ORKA shows embedded TextAE (abstract with highlighted annotations)
- user selects a PubAnnotation-annotation
- ORKA records the PubAnnotation annotation URI as supporting evidence in the nanopublication
Scenario 3: create and cite annotation (extension of Scenario 2)
- if none of the existing annotations are suitable evidence:
- user creates a new PubAnnotation-annotation in TextAE (consider adding step-by-step guidance)
- proceed as in S2
Notes
- Note the difference between “ORKA annotations” (curator says relation X should actually be Y with evidence Z) and “PubAnnotation annotations” (essentially just markup of entities and relations in the text). In this proposal evidence for the former type of annotation is provided by a reference to the latter.
PubAnnotation supports markup of relations between entities: Cancer “caused by” Smoking. In PubAnnotation, projects containing entity-type annotations are in the majority. Perhaps we could consider a process where ORKA users follow a step-by-step wizard to identify their evidence: 1) select subject term, 2) select object term and 3) select predicate term.
The previous note’s suggestion as well as S3 create new content that may be pushed into PubAnnotation.
PubAnnotation is still in active development: PubMed/PMC corpora are not complete, many annotation contributions are not yet public. However, PubAnnotation will likely scale up in the near future.
- In S2 we want a URI to refer to an individual annotation: currently not supported by PubAnnotation. In discussion with PubAnnotation developers to add this feature.
PubAnnotation aims to store annotations, but its community also develops standard APIs for uniform access to on-the-fly annotation webservices. These may prove useful if ORKA users can not find the entities that make up their evidence.
We have evaluated other annotation services like Domeo (Paolo Ciccarese) and Utopia (Steve Pettifer). However, PubAnnotation seems to offer the most straight-forward possibilities for integration with ORKA. In any case, re-use and interoperability of created annotations between the three platforms should be relatively easy (use of APIs and OA ontology).
Assumptions
Requirements
| # | Title | User Story | Importance | Notes |
|---|---|---|---|---|
| 1 | ||||
Questions
Below is a list of questions to be addressed as a result of this specification document:
| Question | Outcome |
|---|---|
| Incentives for curators (to use) and data owners (to link to) the annotator: what are they? Sufficient? | |
How to refer to the original triple source? (Data source = a concept, and is referred to in the resulting nanopublication as a URI)
| |
| What does it mean to “edit” a triple? | It means a new nanopublication is created containing the reference to the "original" nano pub, the new information (new predicate) and adding the provenance of the author. |
| Keep original triple in nanopublication (provenance)? Data source may change. And, "if the datasource changes, what part of the triple or the context do we need to capture in the annotation/nanopublication in order to still understand the triple" | |
| How to map supplied identifiers to reliable RDF URIs? | |
| How to represent a user claim that a triple is wrong or does not exist? Negative associations. | New nanopub |
| Is there a use-case for editing more than a single triple at a time? Is that the same as multiple edits on different triples? | Yes but not for the first version. |
| What does the annotator return to the data source? | In principle: nothing, we publish the nanopub in open access with the provenance, so if for instance BRAIN wants to 'use' the nanopubs to augment the professionally offered graph, they need an 'alert on their UUID' in the provenance. As shown in the user interaction sequences, the Triple Annotator stores the new nanopublication in the NanoPub Store. |
Push annotations back to source? Subscriber model? Or should data sources fetch from nanopub store? | Not in version 1. |
| Do users need credentials? How do we handle authentication? | Login with ORCID. Will stimulate ORCID later we may support other ID's. |
| Licensing of edits; user awareness of license | Newly created nanopubs are OA-only in version 1. Later other licenses may be applied. |
| Who is going to use the annotations? What is the link to SEED articles? | SEED articles: two options: 1. user annotates individual triples after conencting to Open (student) BRAIN, 2. User wants to 'publsih final article and wants to keep annotations 'closed until publication' (needs BRAIN subscription to store annotated graphs and 'publish' annotations later. |
| How to make the annotations findable? | We provide a nanopub store. |
| What makes an annotation trustable? | For everyone to decide, nice thing about asking ORCID is that we have the option to create ORCID know let. |
Not Doing (for this version)
- Support for annotation of multiple triples (subgraph).
- Push annotations back to source.
- Non-OA licenses for nanopubs.
Technical details
Component interaction
The argument for the annotation() call is specified below as "Data Model 1".
Self-referring Annotator calls may be implemented as communication between annotator front-end and back-end.
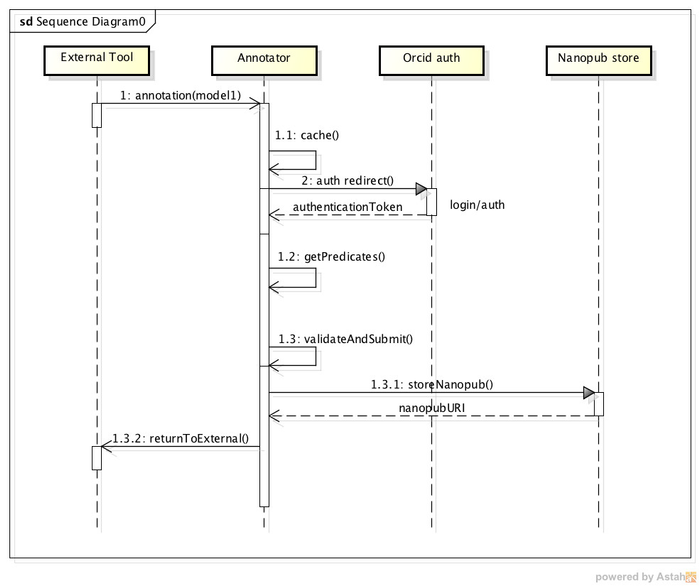
APIs
Annotation (implemented)
type: GET
path: http://semlab1.liacs.nl:8081/annotator/entry
parameter 1: original triple and referrer (see JSON model 1)
desc: entry point for external tools to initiate annotation
returns: -
Get Predicates (used internally to cache list of predicates)
type: GET
path: /annotator/predicates
parameter 1: -
desc: list known predicates, a simplistic approach in making a static list of predicates available
returns: an array of predicate URIs and a label (see JSON model 2)
JSON data model 1
Current:
{
"subject": "aspirin", // original triple subject
"subjectUri": "http://example.com/aspirin",
"predicate": "treats", // original triple predicate
"predicateUri": "http://example.com/treats",
"object": "smoking", // original triple object
"objectUri": "http://example.com/smoking",
"returnUri": "http://semlab1.liacs.nl:8081/annotator-demo/complete.html", // return button url
"returnLabel": "Annotation Demo" // return button label
}Extensions under consideration:
The optional referrer_context enables the tool that links to the annotator to capture any additional provenance or context in the final nanopublication. This may include e.g. a version number of the dataset that is being annotated, or an internal identifier that can be used to retrieve an annotation nanopublication at a later time. Keys have to be valid RDF predicates and values have to be valid RDF resources or literals.
“referrer_context”: {
key1: value1, // keys should be an RDF predicate
key2: value2, // values are RDF resources or literals
...
}
}
Data model 2
[
{“uri”: “http://example.org/rel#treats”, “label”: “treats”},
{“uri”: “http://example.org/rel#affects”, “label”: “affects”},
...
]